Некоторое время назад вместе с моей аспиранткой Мариной Даньшиной подготовили тезисы для Зимней сессии Междисциплинарного форума «КроссЛингва-2013», в которых кратко раскрыты подходы к использованию методов машинного перевода для дешифровки знаменных песнопений. Подробнее о проекте — http://it-claim.ru/semio.
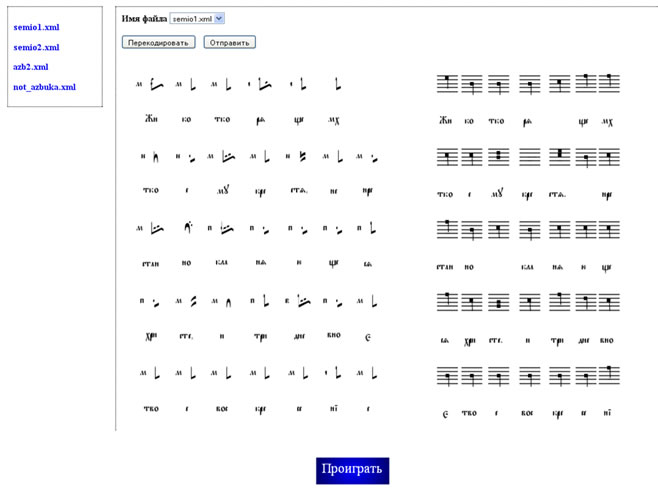
Современная технология записи нот на линейках проста в понимании и позволяет передать мелодии с высокой точностью, однако до ее изобретения и повсеместного распространения использовались другие музыкальные системы. Например, в певческой культуре Древней Руси широко использовалась знаменная нотация, которая состояла из множества специальных знаков, называемых крюками или знаменами. Они имели сложную структуру и соответствовали комбинации нот различной высоты и длительности.
Первые музыкальные рукописи – церковные песнопения ‑ не содержали подсказок исполнителю о высоте или длительности нот, что вызывало трудности для правильного исполнения, поэтому в более поздние музыкальные записи стали добавлять специальные пометы. Распространение нотолинейных музыкальных систем привело к появлению специальных книг (азбук), в которых фиксировались правила расшифровки (дешифровки) знамен и их комбинаций, а также особого класса рукописей – двузнаменников (двознаменников), которые содержали описания правил исполнения в двух нотациях – знаменной и линейной.
Такие книги можно считать аналогами параллельных корпусов текстов на разных языках, и именно они являются главным источником информации для расшифровки знаменных песнопений. Общее количество знамен, с помощью которых производилась запись, оценивается по-разному. В нашем исследовании было экспериментально выявлено более 200 различных знамен, которые могут переводиться одной или несколькими нотами. Помимо этого следует учитывать, что рукописи содержат специальные структуры (фиты, лица), которые как и фразеологизмы в тексте необходимо интерпретировать особенным образом.
Для расшифровки древних безлинейных нотаций применяются два подхода:
- ретроспективный ‑ от более поздних (с наличием подсказок и азбук) ‑ к более ранним рукописям;
- прогрессивный ‑ начинают изучение с самых древних форм и прослеживают их развитие с течением времени.
Первый подход затруднен тем, что имеющиеся двузнаменники и азбуки неполны и противоречивы, а их всесторонний анализ трудно реализуем без средств автоматизации. В рамках второго подхода требуется построение динамической модели развития музыкальных систем записи, с научно обоснованным указанием причин и механизмов тех или иных изменений. Подобная исследовательская деятельность еще более сложна для формализации, т.к. требует работы с большим количеством исторических фактов, которые представлены в многочисленных древних рукописях и могут быть по разному интерпретированы.
В рамках проекта «Компьютерная семиография» (http://it-claim.ru/semio) для дешифровки знаменных песнопений предлагается использовать методы машинного перевода (МП), которые можно разделить на три основные группы:
- прямой (пословный) перевод,
- перевод с помощью лингвистических правил,
- статистический перевод на основе корпусов параллельных текстов.
Несмотря на полувековую историю МП и множество исследований в области лингвистики, на сегодняшний день еще не созданы системы автоматического перевода с одного языка на другой, способные заменить человека. В области компьютерной расшифровки древнерусских музыкальных рукописей делаются только первые шаги, да и музыкальные модели менее изучены, поэтому и здесь реализовать полностью автоматическую систему перевода из одной нотации в другую пока невозможно. В связи с этим в проекте «Компьютерная семиография» реализуются задачи по созданию конкретных инструментов, позволяющие автоматизировать рутинные операции и проводить проверку различных гипотез.
При поддержке гранта Российского гуманитарного научного фонда №110412025в «Автоматизированная система научных исследований в области компьютерной семиографии (АСНИ КС)» был разработан ряд сервисов, предназначенных для экспертов в области музыкальной медиевистики, которые помогают осуществлять перевод из знаменной в нотолинейную нотацию, и обосновывать его научно.
На их основе была спроектирована компонентная методика автоматизированной дешифровки, которая включает модели, методы, алгоритмы, реализованные программные комплексы, результаты статистических исследований и рекомендации, а также шрифты, технологии ввода и структуры данных, которые учитывают специфику знаменной нотации.
Для автоматизации задач перевода в качестве основных исходных данных были выбраны четыре типа музыкальных рукописей:
- музыкальные азбуки, которые представляют собой сборники простых продукционных правил и позволяют реализовать прямой («познаменный») перевод;
- кокизники (сборники фит и лиц), которые описывают особенности прочтения некоторых сочетаний знамен, не сводимых к познаменному переводу.
- сборники попевок, которые содержат перечни устойчивых «музыкальных сочетаний» и позволяют выявлять «законченные» фрагменты песнопений, а также специфику правил их исполнения.
- двузнаменники – корпусы «параллельных музыкальных текстов», которые могут использоваться как для статистического перевода, так и для выявления внутренних законов (правил) построения знаменных песнопений.
Для обработки каждого типа рукописей предложены отдельные инструменты и технологии. Например, для перевода на основе азбук можно составить список продукционных правил с приоритетами и осуществить экспериментальную дешифровку в музыкальном проигрывателе, который показывает результаты перевода не только визуально, но и дает возможность проанализировать мелодию на слух. Приоритеты используются в тех случаях, когда при дешифровке нужно переводить сочетания знамен.
Для анализа двузнаменников разработаны и апробированы различные технологии статистического перевода:
- методы построения «модели языка«:
- с помощью программного комплекса SemioStatistic, который позволяет вычислить вероятности встречаемости знамен и их комбинаций.
- на основе N-граммной модели – вероятность следования знамени определяется с учетом вероятностей предшествующих знамен.
- построение «модели перевода» в зависимости от характера «знаменных конструкций» (их размерности) может быть реализовано на основе:
- текстовых фраз, которые сопровождают нотную запись – выбираются последовательности знамен, соответствующие предложению или его части (до знака препинания);
- попевок – устойчивых сочетаний знамен из соответствующих сборников, составленных вручную древними авторами или исследователями;
- фиксированного контекстного окна – выбранного количества знамен (используется в N-граммной модели).
В перспективе планируется дополнить механизмы перевода методами синтаксического анализа, построенными на основе выявленных моделей (см. предыдущий пост — http://blogs.it-claim.ru/andrey/2012/11/05/musical-infocognitive-technologies-and-znamennye-chant/), а также разработать возможность гибкой настройки параметров дешифровки.
Если кого-то заинтересовала эта тематика, то рекомендую дополнительно посмотреть публикации Лаборатории Анализа Данных Института математики им. С. Л. Соболева СО РАН совместно с Новосибирской консерваторией им. М. И. Глинки по проекту «Электронные азбуки для дешифровки знаменных песнопений«.