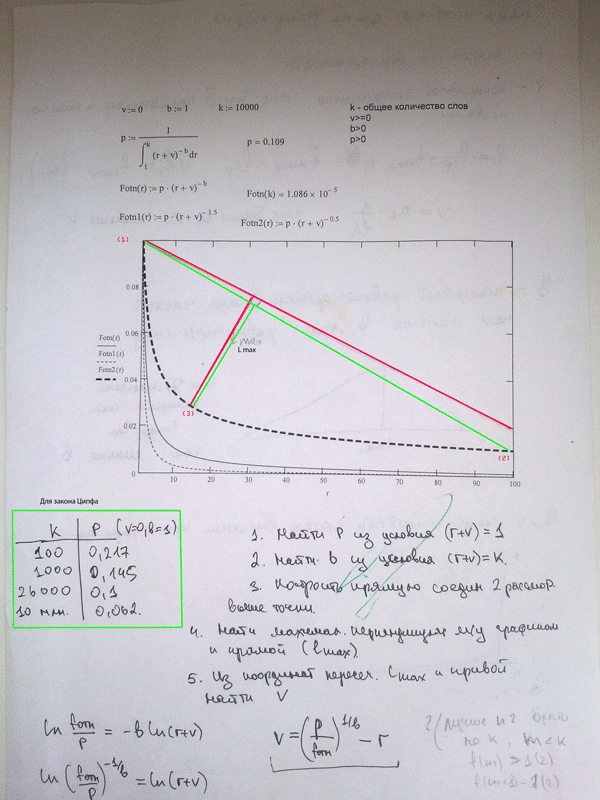
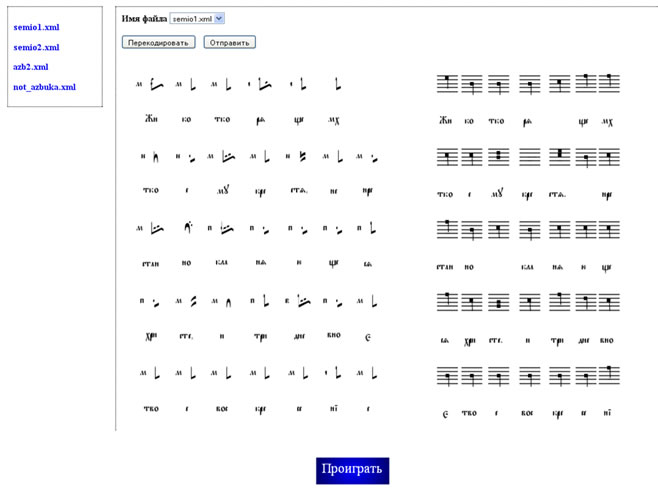
Некоторое время назад мне удалось систематизировать некоторые (к сожалению не все) наработки одной из моих аспиранток — Ирины Голубевой (Даньшиной), и мы написали с ней статью «Исследование синтаксиса семиографических песнопений». В ее вступительной части предпринята попытка показать значимость проводимых нами исследований не только в задачах сохранения древней культуры России, но и в фундаментальных вопросах изучения человека с точки зрения инфо-когнитивных технологий. Я надеюсь, что сомневающие в перспективности и практической значимости нашего проекта студенты смогут по новому взглянуть на него и осознать существо хоть и «долгой», но все-таки инновации, и возможно даже революционной )))
Одним из перспективных направлений развития инфо-когнитивных технологий является исследование механизмов работы невербального сознания людей. Особое место в изучении этих вопросов занимают музыка и связанные с ней когнитивные процессы, которые часто находятся в тесной связи с речевой деятельностью человека.
Музыка также как и язык является предметом коммуникации и не существует вне общения людей [1], поэтому она всегда выступает результатом некоторого человеческого посредничества или исполнения, хотя источниками звуков могут служить различные природные и техногенные явления.
Для объяснения близости двух когнитивных систем выдвинута гипотеза о том, что музыка и язык развивались из общего предка – «музолингвальной системы» («musilanguage system»), которая и определила их общие признаки [2]. По мере развития две системы приобрели самостоятельные и уникальные черты, однако по-прежнему тесно взаимодействуют между собой.
Исследователи в области нейролингвистики полагают, что письменная речь является отражением мыслительных процессов человека и раскрывает законы языкового мышления. Это дает основания предположить, что и музыкальные записи хранят в себе ответы на вопросы об устройстве невербального сознания, его эмоциональной, культурной и других составляющих.
Создание графических средств, позволяющих зафиксировать музыкальные произведения на бумаге, явилось революционным событием в истории музыки и тесно связано с развитием письма в целом ‑ первые системы языкового и музыкального письма появились в одних культурах и принадлежат одному типу письма. [13]
Записи музыки, как и записи речевых сообщений, начинались с рисунков, которые постепенно эволюционировали в направлении к пиктографии и иероглифике. Об этому свидетельствуют первые рисуночные и иероглифические жреческие записи музыки, которые были найдены в Древнем Египте [13]. Несколько веков спустя, в VI-VII вв. в европейской (греческой) церковной музыке появляется невменная нотация, которая, трансформируясь, развивается в Византии и вместе с христианством приходит в древнерусские песнопения.
Музыкальные произведения Руси XI-XVII веков записывались с помощью специальной музыкальной системы (нотации), которую принято называть знаменной или семиографической. Она содержит нескольких сотен знамен (крюков), каждому из которых соответствует определенная последовательность звуков различной длительности и высотности.

Во время Петровских реформ знаменная нотация была заменена на «итальянскую» ‑ более простую и современную ното-линейную систему, которую мы используем и по сей день. К сожалению, во время преобразований был утрачен «ключ» к расшифровке мелодий, что не позволяет однозначно перевести многие старинные песнопения в современное представление.
Вместе с тем музыкальные записи, начиная с первой половины XVII века, имеют дополнительные обозначения относительной высоты звуков и длительности, которые являются «подсказками» исполнителю. Это позволяет анализировать их, и переносить полученные знания на песнопения более ранних периодов. Однако для полной расшифровки необходимо выявлять в знаменной нотации внутренние законы, в силу которых мелодии записывались с помощью одних знамен, а не других.
Для решения этой задачи в рамках проекта «Автоматизированная система научных исследований в области компьютерной семиографии (АНСИ КС)» выдвинута гипотеза о наличии в знаменных песнопениях определенной семиотической системы, близкой по своей структуре и механизмам к естественному языку. Это позволяет применять лингвистические методы для обработки и анализа песнопений, выявления их музыкального «лексикона», синтаксиса, семантики и прагматики.
В случае всестороннего подтверждения указанной гипотезы будут достигнуты не только ценные результаты по сохранению богатого наследия национальной певческой культуры, но и открыты новые фундаментальные механизмы музыкальных инфо-когнитивных технологий.
Музыкальная семиотика
Знаменные песнопения являются одной из множества знаковых систем, которыми люди пользуются в целях коммуникации, передавая музыкальные сообщения о своих мыслях, чувствах, переживаниях. Знаки в музыке и образуемые ими знаковые системы изучает музыкальная семиотика, в рамках которой в настоящее время сформулировано множество различных теорий, моделей и подходов: Теория восприятия и понимания мелодий ‑ модель Implication/Realization (I/R) [3], Парадигматический анализ [4,5], Порождающая Теория Тональной Музыки (GTTM) [6] и др.
Разработанные подходы не могут быть напрямую применены для анализа и расшифровки знаменных песнопений, т.к. они опираются на современную ното-линейную систему и не учитывают специфику семиографического представления. Однако в перспективе, после получения вариантов расшифровки, можно осуществить оценку указанных теорий на предмет их применимости для разрешения многозначности трактовок.
Для использования лингвистических методов при анализе песнопений были проведены «лингво-музыкальные» аналогии (таблица 1) и выделены соответствующие семиотические конструкции в музыкальных произведениях. Основными элементами семиографических песнопений являются знамена, которые чем-то похожи на иероглифы – они имеют уникальные графемы, сформированные из базовых и дополнительных элементов («знамем»), соответствуют мелодиям и напевам (последовательности нот определенной высоты и длительности). Знамена в свою очередь могут комбинироваться в более сложные структуры – попевки, фиты, лица и другие музыкальные фигуры.
Если Вас заинтересовала эта тематика, то продолжение читайте в полной pdf-версии статьи. В блог их переложить трудоемко, т.к. там много, специальных символов, таблиц и рисунков )