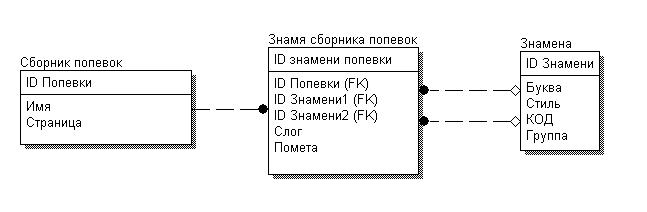
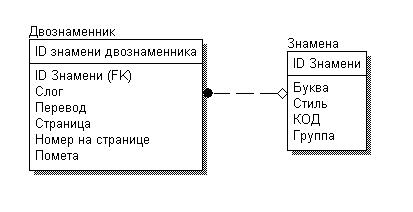
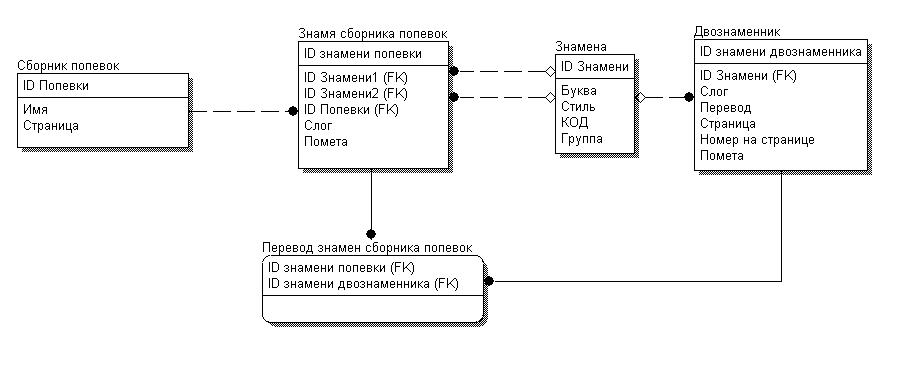
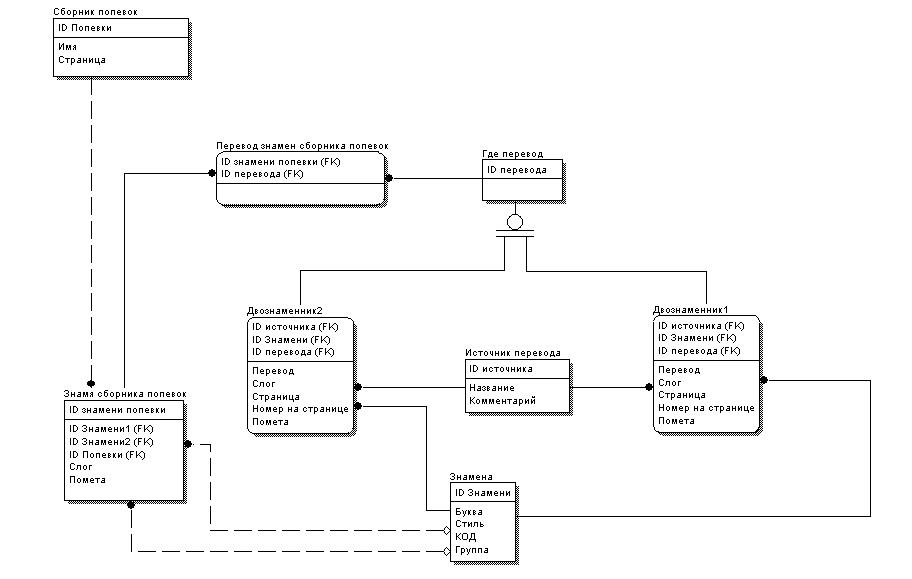
21 апреля прошла первая лекция в Открытом университете Сколково. В качестве лектора был приглашен Уильям Хазелтайн – всемирно известный ученый и предприниматель, один из первых исследователей в области СПИДа, основатель компании Human Genome Sciences Inc.
Он поделился своим опытом и выделил главные вещи. Вот основные, на мой взгляд, тезисы:
1. Необходимость привлекать лучшие умы, чтобы они были заинтересованы развивать науку в течении многих лет. То есть недостаточно просто пригласить хороших специалистов, необходимо также их заинтересовать.
2. Недостаточно просто дать человеку образование и среду — необходимы две вещи:
1)примеры 2) свобода.
Под примерами он имеет в виду следующее:
Во-первых, необходимо выделить великую проблему, которой хочешь заниматься всю жизнь. (Это уникальная характеристика — уметь признавать великую проблему)
Во-вторых, необходимо иметь хорошего наставника. Чтобы решить проблему, которую ты выбрал для себя, нужно найти лучшего специалиста во всем мире и ехать к нему.
Под свободой понимается то, что тебе не говорят конкретно что делать, какой проблемой заниматься. Ты должен сам ставить перед собой задачу и самостоятельно отвечать за свой выбор, конкурировать с другими специалистами, которые также работают в этой области.
3. Необходимо найти баланс между интересами науки и бизнеса. Ему, например, с самого начала своей деятельности приходилось кроме занятий исследованиями находить деньги на реализацию своих проектов, выигрывать гранты. Для этого надо «чтобы тебя знали», а значит много публиковаться и ездить на конференции. Это был его «бизнес». Получается, что бизнес и наука имеют много общего.
достижения -> публикации -> деньги
4. Университет — инструмент, который дает образование и ответы на вопросы.
5. Прежде чем начать чем-то заниматься, нужно ответить на следующие вопросы:
1) необходимость
2) готовность технологий
3) есть ли люди, которые будут этим заниматься (готовы ли они)
Хотелось бы отметить, что научно-образовательный кластер CLAIM как раз действует в этом ключе 🙂
1) лучшие научные руководители
2) площадка для публикаций
3) средство коммуникации студентов и аспирантов
4) информация о конкурсах и грантах
5) участие в конкурсах и получение грантов
p.s. заметка написана совместно с коллегой Ириной Даньшиной