
Исследование нейросетевого алгоритма
для задачи распознавания речи (март 2012)
После предыдущего поста мною достигнуты новые результаты.
Написаны и исследованы новые методы обучения нейронной сети. Напоминаю, что используемая сейчас нейронная сеть имеет прямые связи. Все имеющиеся способы обучения, кроме метода Монте-Карло, являются модификациями метода обратного распространения ошибки.
Среди написанных:
- Обычный последовательный метод.
- Метод многократного распространения ошибки.
- Групповой метод, в том числе с адаптивным шагом.
- Групповой метод поиска.
- Групповой метод случайного поиска (метод Монте-Карло)
При использовании всех методов очень ощутима основная проблема обучения нейронных сетей: она впадает в локальный минимум функции, не доходя до глобального. Из-за этого не достигаются очень хорошие результаты.
Алгоритм нахождения спектральных пиков полностью отлажен. Пики устойчиво выделяются на гласных и сонорных звуках. Преимущества подавания на вход нейронной сети амплитуд спектральных пиков в порядке их нумерации вместо всего спектра по-началу были очевидны: это одновременно и небольшой объем информации для сети, и вполне достаточный. Вы можете видеть это на Рис.1. Голосовые звуки (в которых есть гармоники – спектральные линии) очень хорошо различаются по количеству гармоник и их интенсивности(амплитуде). Также преимущество данного набора в том, что он инвариантен к изменениям громкости голоса и высоты тона (при этом спектральные пики смещаются по частоте, не изменяясь по количеству и амплитуде).
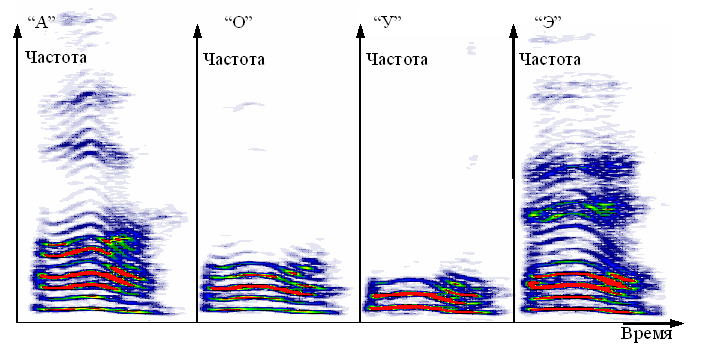
Рис.1 Спектральные диаграммы “время-частота” для гласных звуков
Но на самом деле количеству пиков при изменении тона может меняться. При повышении высоты голоса спектральные пики начинают пропадать. При этом изменяется звук. Для слуховой визуализации этого сделан простейший синтез звука. В результате при повышении тона произношения звука “А” сначала при синтезе слышется звук “А”, а затем что-то среднее между “О” и “У”. Это особенность голосового резонатора. Из-за этого ранее сеть не очень хорошо тренировалась и ошибка оставалась не очень хорошей.
Недавно было проведено следующее исследование: на вход нейронной сети подавалась огибающая всех пиков. Результаты получались немного лучше, чем при предшествующем способе, но не сильно.
Очевидно, что дальше следует двигаться в направлении анализа всего спектра, а не только спектральных пиков, что и будет исследоваться в ближайшем будущем.
Кроме гласных звуков, также достигнуты некоторые успехи в распознавании согласных сонорных звуков (л,н,м,р,(в)), спектр которых также имеет только голосовые компоненты (без шумовых). Даже распознаются некоторые сочетания звуков.
Разработана пользовательская программа для простейшего управления компьютером «Voice Commander», которая может выполнять следующие голосовые команды(пока что): открыть блокнот, открыть Paint, открыть Word, открыть Internet Explorer, открыть справку о программе, закрыть окно, остановить запись звука в реальном времени, выключить компьютер. Эти действия выполняются при произнесении соответствующих звуков. Также можно выводить произнесенную речь. Программа распознает гласные и согласные сонорные звуки.
Внешний вид программы вы можете видеть на Рис.2
 .
.
Рис.2 “Voice Commander”.
К сожаланию, рабочая версия программы не будет сейчас залита. Она будет доступна для общего скачивания только тогда, когда достигнутся лучшие результаты распознавания; когда сеть будет натренирована на многих людях.
Исследование нейросетевого алгоритма
для задачи распознавания речи (ноябрь 2012)
Я начал делать этот проект мае 2011 года. Программировать я решил на языке
C++, точнее с помощью программы Microsoft Visual C++.
Изначально задачей проекта было распознавать фразы, разделяя слова по смыслу. В ходе работы я понял, что это слишком глобальная задача и справиться с ней будет сложно и потребуется очень много времени на ее реализацию. Поэтому я пока что остановился на более простой задаче: распознавание гласных и согласных. Следующей задачей является создание модуля, с помощью которого можно будет управлять некоторыми внешними программами(например, нажимать кнопки с помощью голоса). Это является хорошей демонстрацией работы программы.
На данном этапе я научился распознавать гласные звуки, но, пока что, не на должном уровне из-за проблем, которые я укажу ниже. Надеюсь, что эти проблемы в ближайшем будущем будут решены. Для распознавания гласных и согласных звуков я пишу 2 отдельные нейронные сети.
Итак, первом делом над входным сигналом производится быстрое преобразование Фурье. Я выполняю его с помощью библиотечных функций.
Затем находятся амплитуды спектральных пиков на участках времени, на которых прослеживается произнесение звуков. На данном этапе данный алгоритм работает не очень хорошо(не везде правильно находятся пики). Из-за этого нейронная сеть недостаточно хорошо обучается. Эти амплитуды подаются на вход нейронной сети, распознающей гласные звуки.
Нейросеть является многослойной.
Её структуру можно представить следующим образом:
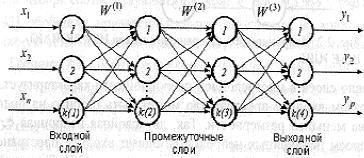
В программе количество слоев и количество нейронов в каждом слое настраивается. В настройках доступны 3 основные функции активации: сигмоидная, бисигмоидная функции, гиперболический тангенс. Функция активации может быть выбрана для каждого слоя отдельно. Для обучения нейронной сети используется метод обратного распространения ошибки.
Вот картинка, демонстрирующая работу моей программы на данном этапе:
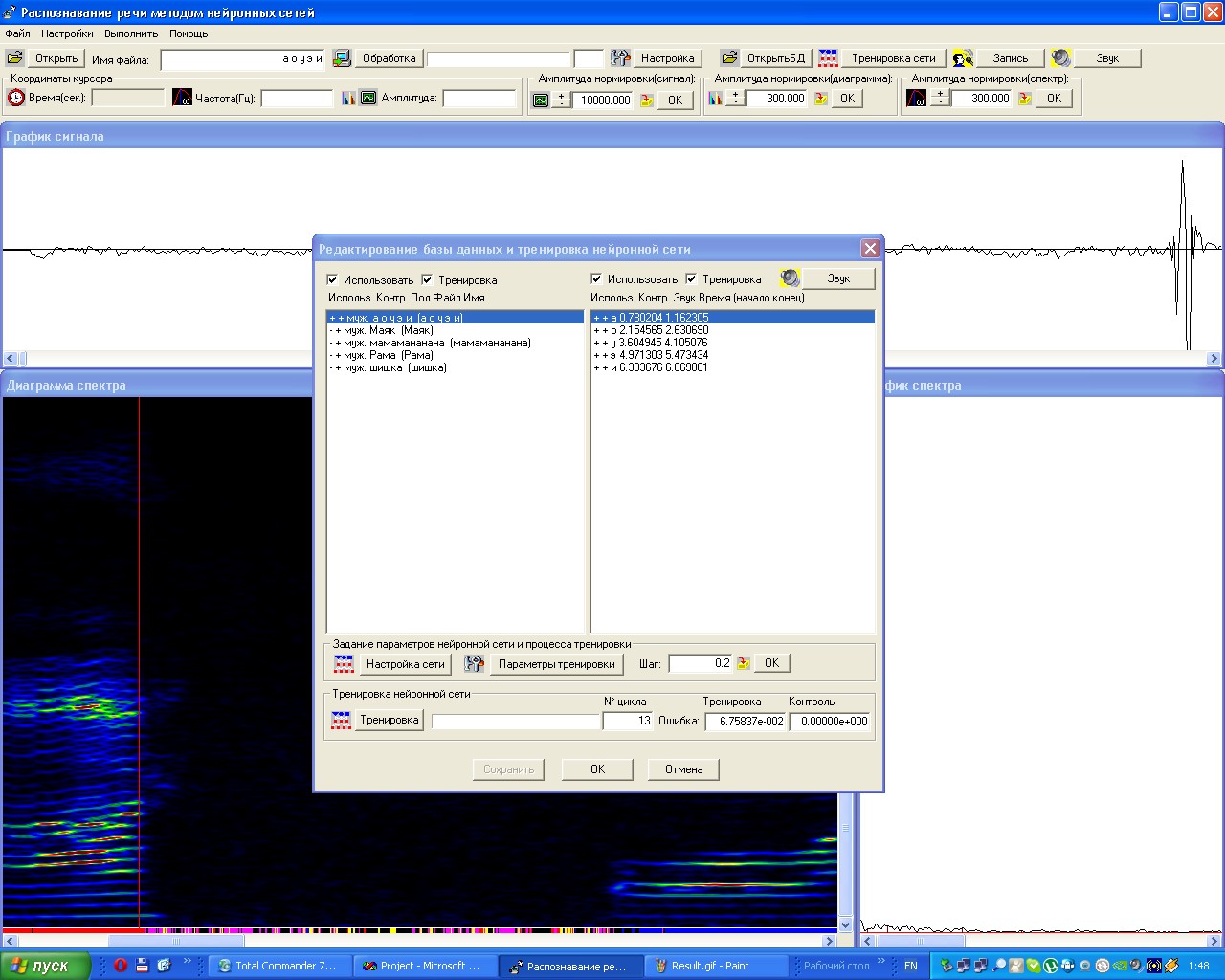
Под спектральной диаграммой(по оси x – время, по оси y – частота, цвет показывает амплитуду) находится узкая полоска, по которой проверяется правильность распознавания. Под каждой буквой цвет должен быть постоянен(на картинке вы можете видеть гласные «а» и «о». «а»- красный цвет полоски, «о» — синий). Там, где человек ничего не говорит, полоска должна быть чисто черная. На картинке такое не происходит из-за того, что алгоритм нахождения пиков не доработан и в некоторых местах неправильно работает. Также из-за этого ошибка достигается недостаточно маленькая(порядка 10e-002, вы можете видеть ее на картинке).
Пока что я еще не знаю, что лучше подавать на вход нейронной сети, распознающей согласные звуки, чтобы все хорошо работало.
В общем, еще есть множество проблем, которые я постепенно решаю.