Информационная система онлайн кластеризации
Сервис предоставляет возможность кластеризации числовых данных с использованием методов Minimum Spanning Tree и Fuzzy C-means
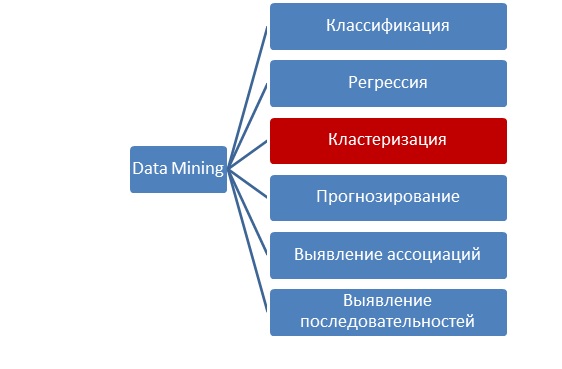
В связи с ростом объемов информации в последние десятилетия актуальность приобретают новые способы обработки и работы с данными. Одним из таких направлений является Data Mining – интеллектуальный анализ данных (анализ фактографических данных). В отличие от классических способов работы с информацией, в это области большое внимание уделяется поведению человека, решающего сложные интеллектуальные задачи классификации, обобщения, выявления закономерностей и т.д. Развитию этой дисциплины способствовало проникновение в сферу анализа данных теории искусственного интеллекта. Data Mining – это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний. При исследованиях и работе с данными в рамках Data Mining выделяют шесть различных задач – классификация, регрессия, кластеризация, выявление ассоциаций, выявление последовательностей и прогнозирование.
В данной работе используются методы кластерного анализа данных. Основной целью кластерного анализа является нахождение сравнительно небольшого числа групп (кластеров) объектов так, чтобы внутри кластеров объекты были как можно более схожи, а между кластерами – как можно больше отличались. Этот вид анализа широко используется в информационных системах при работе с категорийными данными в таких областях как статистика, финансовая математика, при проведении социально-экономических исследований, в банковской и страховой сферах, в медицине и так далее.